WHAT IS ALPHA TESTING ?

alpha Testing
Alpha testing is an internal form of acceptance testing conducted by an organization’s own employees before releasing a product to external users. It aims to identify bugs and issues within the software to ensure it meets the specified requirements and functions as intended. This testing phase typically involves both black-box and white-box testing techniques and is performed in a controlled environment that simulates real-world usage.
The alpha testing process generally includes two phases:
- Internal Testing by Developers: Developers perform initial tests to identify and fix obvious issues.
- Testing by Quality Assurance (QA) Teams: QA teams conduct more thorough testing to uncover additional bugs and assess the software’s overall performance and stability.
By conducting alpha testing, organizations can detect and resolve critical issues early in the development cycle, leading to a more stable and reliable product before it undergoes beta testing with external users
Alpha Testing Process
Alpha testing is a crucial phase in the software development lifecycle, conducted to identify and rectify issues before releasing the product to external users. This internal testing process ensures that the software meets the specified requirements and functions as intended.
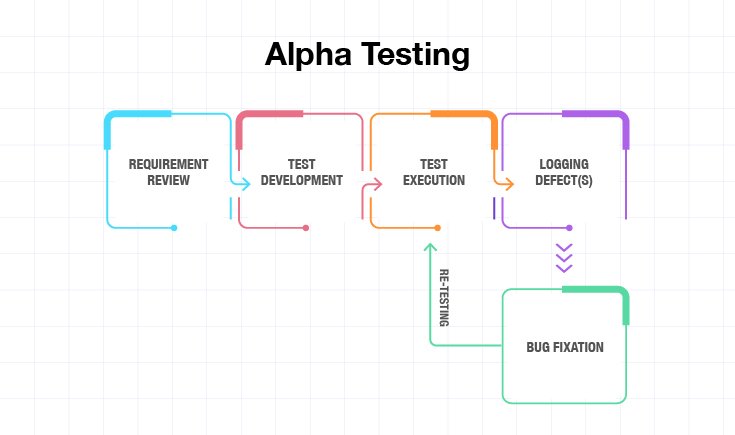
The alpha testing process typically involves the following steps:
- Requirement Review: Developers and engineers evaluate the software’s specifications and functional requirements, recommending necessary changes to align with project goals.
- Test Planning: Based on the requirement review, a comprehensive test plan is developed, outlining the scope, objectives, resources, schedule, and methodologies for testing.
- Test Case Design: Detailed test cases are created to cover various scenarios, ensuring that all functionalities are thoroughly examined.
- Test Environment Setup: A controlled environment is established to simulate real-world conditions, providing a stable setting for testers to execute test cases.
- Test Execution: Testers perform the test cases, documenting any defects, bugs, or performance issues encountered during the process.
- Defect Logging and Tracking: Identified issues are logged into a defect-tracking system, detailing their severity, steps to reproduce, and other pertinent information.
- Defect Resolution: The development team addresses the reported defects, implementing fixes to resolve the identified issues.
- Retesting: After fixes are applied, testers re-execute relevant test cases to confirm that the defects have been successfully resolved and no new issues have arisen.
- Regression Testing: To ensure that recent changes haven’t adversely affected existing functionalities, a comprehensive set of tests is run across the application.
- Final Evaluation and Reporting: A test summary report is prepared, highlighting the testing outcomes, unresolved issues, and overall product readiness for the next phase, typically beta testing.
By meticulously following this process, organizations can enhance the quality and reliability of their software products, ensuring a smoother transition to subsequent testing phases and eventual market release.
who perform Alpha Testing ?
Alpha testing is typically conducted by internal teams within an organization. This includes software developers, quality assurance (QA) professionals, and sometimes other employees who are not part of the development team. Developers perform initial tests to identify and fix obvious issues, while QA teams conduct more thorough testing to uncover additional bugs and assess the software’s overall performance and stability. In some cases, non-technical staff may also participate to provide insights into real-world scenarios and user experiences.
- Early Detection of Defects: Identifying and addressing issues during alpha testing helps prevent them from reaching end-users, enhancing the overall quality of the software.
- Improved Product Quality: By simulating real-world usage in a controlled environment, alpha testing ensures that the software functions as intended, leading to a more reliable product.
- Cost Efficiency: Detecting and fixing bugs early in the development cycle reduces the expenses associated with post-release patches and customer support.
- Enhanced Usability: Feedback from internal testers provides insights into the software's usability, allowing developers to make necessary improvements before the beta phase.
- Limited Test Coverage: Since alpha testing is conducted internally, it may not cover all possible user scenarios, potentially leaving some issues undiscovered until later stages.
- Time-Consuming: Alpha testing can be extensive, requiring significant time to thoroughly evaluate the software, which may delay subsequent testing phases.
- Potential Bias: Internal testers, being familiar with the software, might overlook certain issues that external users could encounter, leading to incomplete identification of defects.
- Resource Intensive: Conducting comprehensive alpha testing demands considerable resources, including personnel and infrastructure, which might strain project budgets.