Bagging In Machine Learning
what is Bagging ?
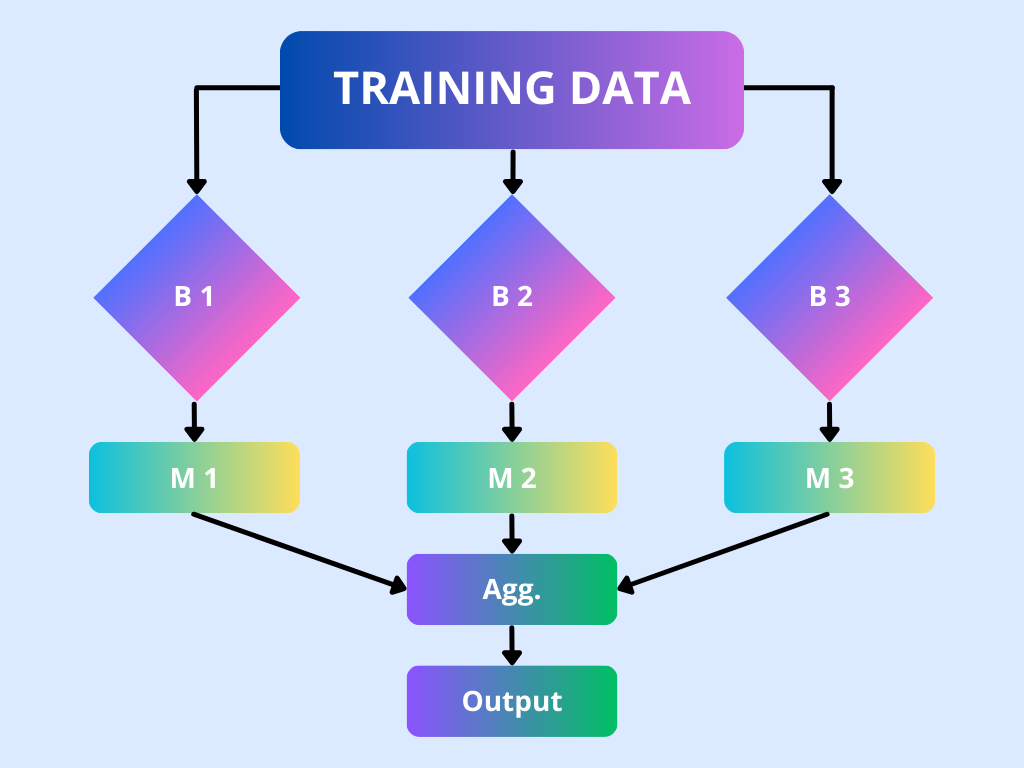
Bagging, an abbreviation for Bootstrap Aggregating, is a powerful ensemble learning technique in machine learning designed to enhance the stability and accuracy of predictive models. By combining the predictions of multiple models trained on different subsets of the data, bagging reduces variance and mitigates the risk of overfitting, leading to more robust and reliable outcomes.
Understanding Bagging

Why Bagging Works ?
Bagging is particularly effective for models that are sensitive to fluctuations in the training data, known as high-variance models. By training multiple models on different subsets of the data and aggregating their predictions, bagging reduces the variance of the final model without increasing the bias. This ensemble approach leads to improved predictive performance and greater robustness.
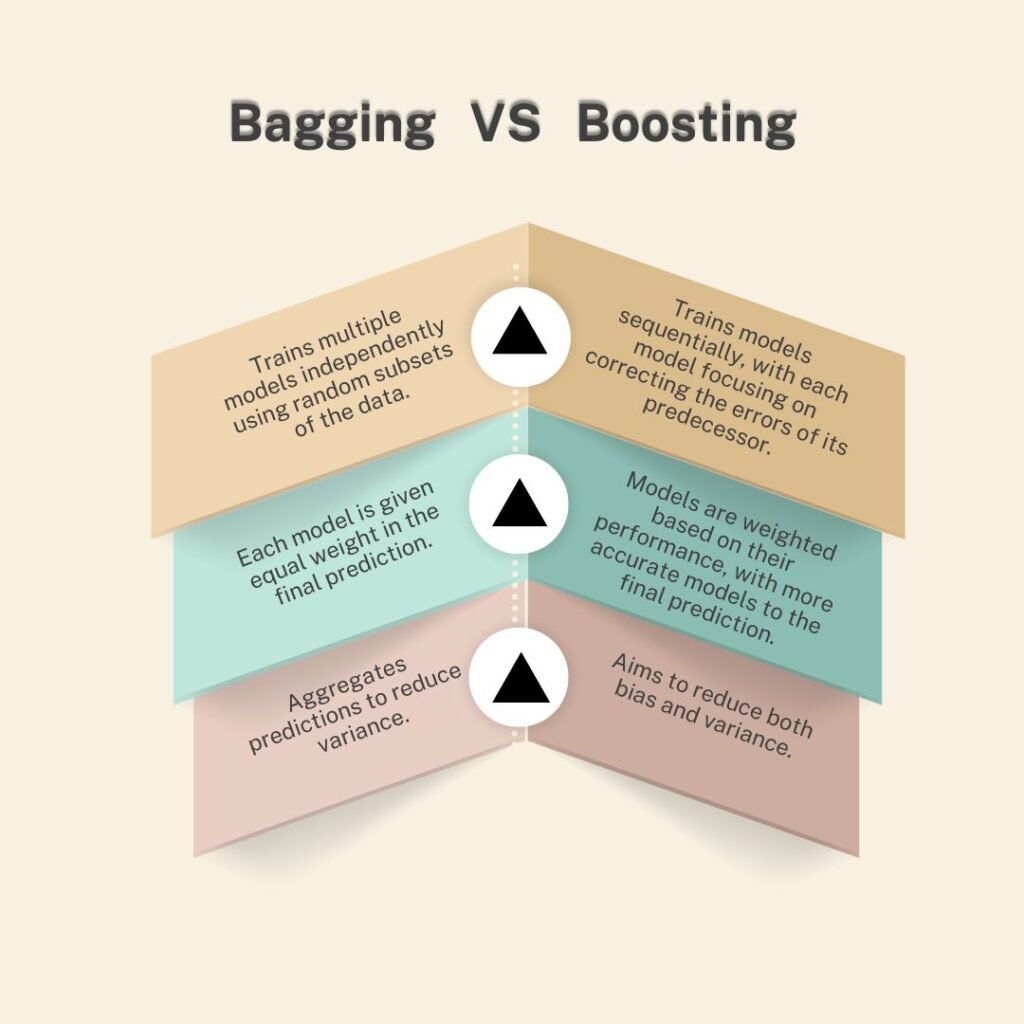
Bagging, short for Bootstrap Aggregating, is an ensemble learning technique designed to enhance the stability and accuracy of machine learning models. It achieves this by reducing variance and mitigating overfitting, particularly in high-variance models like decision trees.
Bagging, or Bootstrap Aggregating, enhances machine learning models by reducing variance and mitigating overfitting. It involves training multiple models on different subsets of the data and aggregating their predictions. This ensemble approach leads to more stable and accurate predictions.
Advantages
- Variance Reduction: By averaging multiple models, bagging reduces the variance of the prediction, leading to improved performance on unseen data.
- Overfitting Mitigation: Combining multiple models helps prevent overfitting, especially in high-variance models like decision trees.
- Parallel Training: Each model is trained independently, allowing for parallelization and efficient computation.
Disadvantages
- Increased Computational Cost: Training multiple models can be resource-intensive, especially with large datasets or complex models.
- Loss of Interpretability: The ensemble of multiple models can be more challenging to interpret compared to a single model
Applications of Bagging
- Random Forests: Perhaps the most well-known application of bagging, random forests build an ensemble of decision trees, each trained on a bootstrap sample of the data. Additionally, random forests introduce randomness by selecting a random subset of features for each split in the decision trees, further enhancing diversity among the trees.
- Regression and Classification Tasks:Bagging can be applied to various base learners to improve predictive performance in both regression and classification problems.
Leave a Reply