What is Data Lake? 6 Powerful Benefits & Best Practices
 Why it is Important?
Why it is Important?
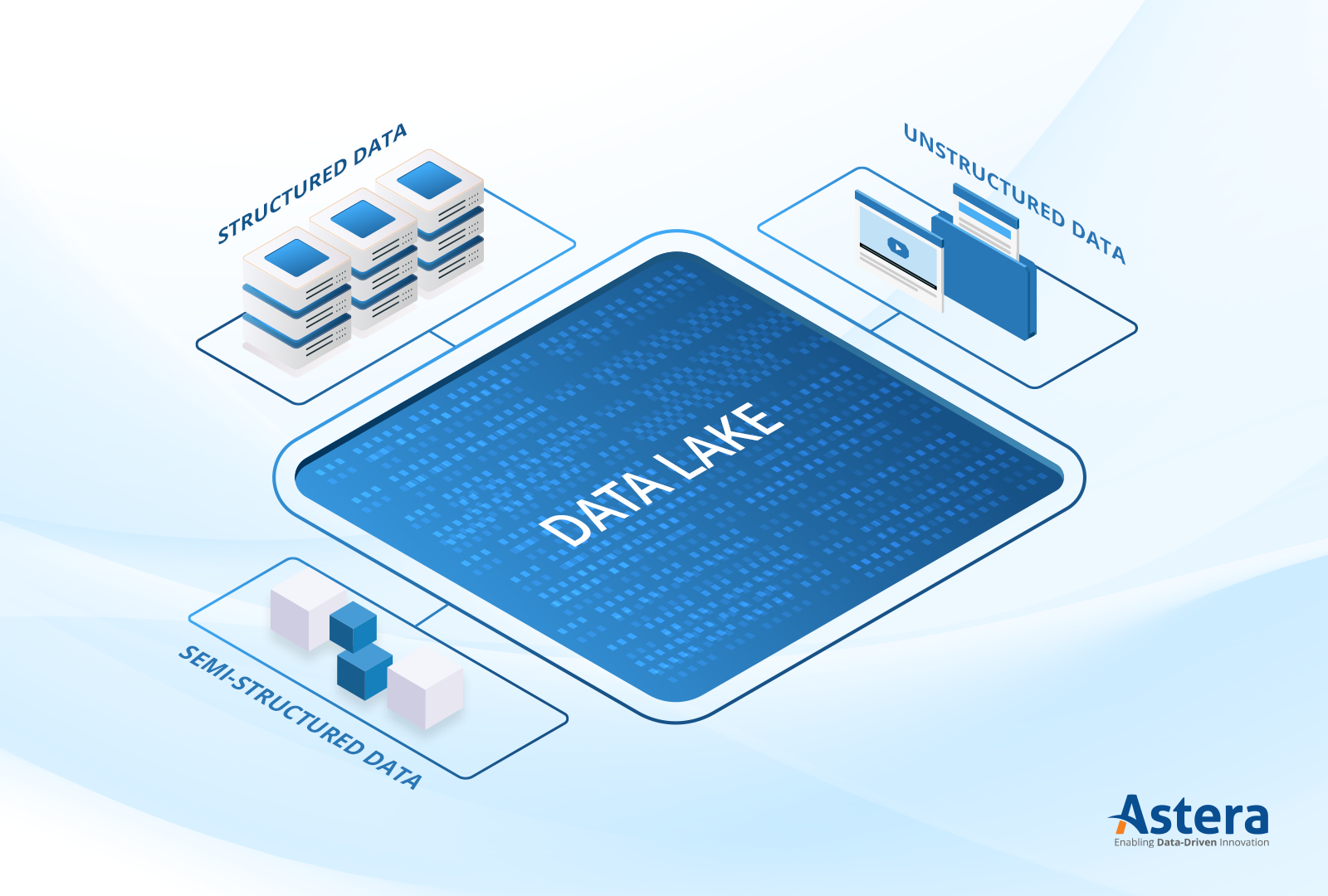
 Handles structured, semi-structured, and unstructured data Supports advanced analytics, AI, and ML Scalable and cost-effective storage solution Enables real-time data processing
Handles structured, semi-structured, and unstructured data Supports advanced analytics, AI, and ML Scalable and cost-effective storage solution Enables real-time data processing
Key Components of a Cloud-based Data Lake Architecture
A Data Lake is built using multiple components to ensure efficient data storage, processing, and analysis.
 Data Ingestion Layer
Data Ingestion Layer 
This layer is responsible for importing data from various sources, including: Databases (SQL, NoSQL) APIs & Web Services Streaming Data (Kafka, Apache Flink) IoT & Sensor Data
Databases (SQL, NoSQL) APIs & Web Services Streaming Data (Kafka, Apache Flink) IoT & Sensor Data
 Storage Layer
Storage Layer 
The storage layer is where data is stored in its raw form. Popular storage options include: Cloud Storage – AWS S3, Azure Data Lake, Google Cloud Storage On-Premises Storage – Hadoop Distributed File System (HDFS)
 Processing & Analytics Layer
Processing & Analytics Layer 
This layer enables data transformation and analysis through: Big Data Processing (Apache Spark, Hadoop, Presto) Machine Learning & AI (TensorFlow, PyTorch, AWS SageMaker) SQL Queries & BI Tools (Power BI, Tableau, Looker)
 Security & Governance Layer
Security & Governance Layer 
This layer ensures data security, compliance, and governance using: Role-Based Access Control (RBAC) Data Encryption & Masking Data Cataloging & Metadata Management
 Consumption Layer
Consumption Layer 
This layer allows users to access and utilize data through: APIs & SDKs for developers Business Intelligence (BI) dashboards Machine Learning models for predictions

Top Benefits of a Enterprise Data Lake
Stores All Data Types – Structured, semi-structured, and unstructured. Scalability – Can handle petabytes of data efficiently. Flexibility – No need to structure data before storage. Cost-Effective – Uses low-cost cloud storage (AWS S3, Azure Blob Storage). Advanced Analytics – AI, ML, and Big Data processing capabilities. Real-Time & Batch Processing – Supports fast decision-making.
Common Challenges in Managing a Big Data Lake
 Data Swamp Problem – If not properly managed, a Data Lake can become a “data swamp” (unorganized and unusable). Solution: Implement metadata tagging and data governance policies.
Data Swamp Problem – If not properly managed, a Data Lake can become a “data swamp” (unorganized and unusable). Solution: Implement metadata tagging and data governance policies.
Security Risks – Storing raw data without security measures can lead to breaches and compliance violations. Solution: Use role-based access control (RBAC), encryption, and logging.
Slow Query Performance – Large volumes of raw data can slow down analytics. Solution: Use indexing, caching, and data partitioning for optimization.
Popular Data Lake Platforms & Tools
 Cloud-Based Data Lakes
Cloud-Based Data Lakes
AWS Data Lake (Amazon S3 + AWS Glue) – Scalable, AI-ready. Azure Data Lake Storage (ADLS) – Microsoft ecosystem integration. Google Cloud Storage (GCS) + BigQuery – Fast SQL-based analytics.
 Open-Source Data Lake Solutions
Open-Source Data Lake Solutions
Apache Hadoop & Spark – Distributed storage & big data processing. Delta Lake – Optimized data lakehouse architecture.
Real-World Use Cases of Data Lakes
 E-Commerce – Customer behavior analysis, recommendation systems. Healthcare – Medical imaging, genomics research, AI-driven diagnostics. Finance – Fraud detection, real-time transaction monitoring. Manufacturing – IoT-based predictive maintenance. Retail & Supply Chain – Demand forecasting, inventory optimization.
E-Commerce – Customer behavior analysis, recommendation systems. Healthcare – Medical imaging, genomics research, AI-driven diagnostics. Finance – Fraud detection, real-time transaction monitoring. Manufacturing – IoT-based predictive maintenance. Retail & Supply Chain – Demand forecasting, inventory optimization.
Best Practices for Managing a Data Lake Storage
Define Data Governance Policies – Helps prevent data swamps. Implement Data Security – Use encryption & role-based access control. Optimize Query Performance – Use indexing, caching, and partitioning. Ensure Data Quality – Maintain metadata tagging and validation rules. Use Cost Optimization Strategies – Store rarely accessed data in lower-cost tiers.
It’s Future: What’s Next?
 Data Lakehouses – A hybrid model combining Data Lake & Data Warehouse capabilities. AI-Powered Data Lakes – Using machine learning for automatic data classification. Real-Time Data Lakes – Enabling instant data processing & decision-making. Edge Data Lakes – Storing & processing IoT data closer to the source.
Data Lakehouses – A hybrid model combining Data Lake & Data Warehouse capabilities. AI-Powered Data Lakes – Using machine learning for automatic data classification. Real-Time Data Lakes – Enabling instant data processing & decision-making. Edge Data Lakes – Storing & processing IoT data closer to the source.
Leave a Reply