What is Boosting in Machine Learning
What is Boosting in Machine Learning ?
In machine learning, achieving high accuracy and model performance is crucial. While there are many ways to improve the performance of machine learning models, one of the most effective techniques is boosting. Boosting is an ensemble learning technique that combines multiple weak learners into a strong learner to improve predictive accuracy. But what exactly does boosting mean in the context of machine learning? Let’s explore this powerful technique and how it can help you create better machine learning models.
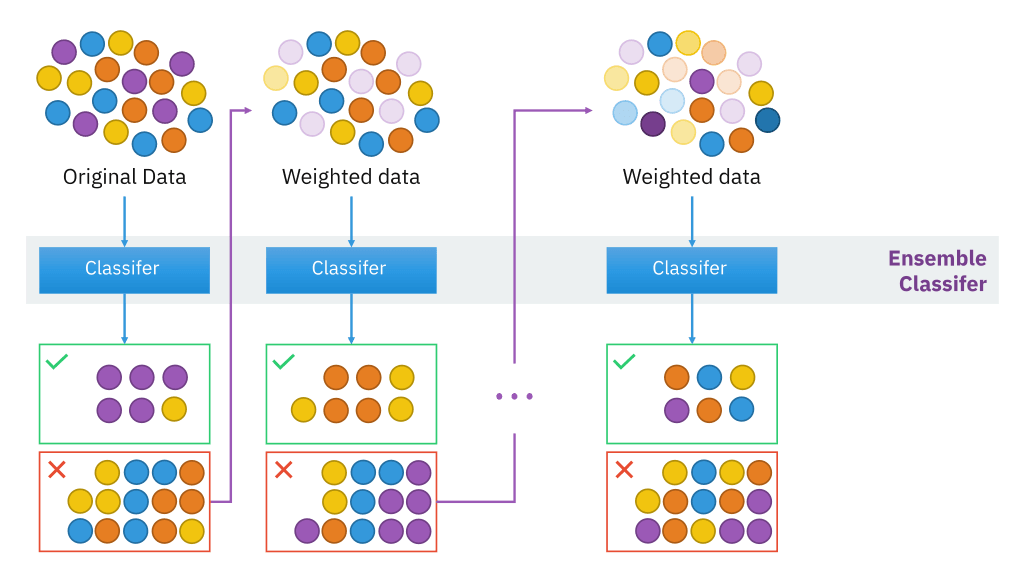
Boosting is an ensemble learning technique that combines the predictions of several models, called weak learners, to create a single, strong predictive model. The primary objective of boosting is to convert weak learners, which are typically simple models like decision trees, into a highly accurate predictive model by combining their outputs. Unlike other ensemble methods such as bagging (which trains multiple models independently), boosting builds models sequentially. Each subsequent model attempts to correct the errors made by the previous models, allowing the overall model to focus on the most challenging instances.
Key Features of Boosting
Before diving into the process of how boosting works, let’s review some key features that define this technique:
Weak Learners: A weak learner is any model that performs slightly better than random guessing. In boosting, decision trees with limited depth (often referred to as decision stumps) are commonly used as weak learners. Despite being weak individually, when combined, these models can make accurate predictions.
Sequential Learning: Boosting algorithms build models one after another in a sequential manner. Each new model corrects the mistakes of the previous model. This is in contrast to bagging algorithms (like Random Forest) where all models are built in parallel.
Weighting Misclassified Instances: In boosting, the instances that are misclassified by previous models are given higher weights, meaning that the next model in the sequence will focus more on those harder-to-classify instances. This helps improve the overall performance of the model.
Final Prediction: After all models have been trained, they are combined to make a final prediction. Depending on the boosting algorithm, this could involve a weighted average of the predictions (for regression tasks) or a majority vote (for classification tasks).
How Does Boosting Work?
The boosting process involves several iterations where weak learners are trained and combined to improve model accuracy. Let’s go through the process step by step:
Start with a Simple Model: The first model (often a weak learner, like a shallow decision tree) is trained on the dataset. This model will likely make several mistakes, as it is a simple model.
Focus on Mistakes: After the first model makes predictions, boosting algorithms will focus on the data points that were misclassified or have large prediction errors. These points will be given higher weights in the next model’s training process, signaling to the new model that these instances need more attention.
Train the Next Model: The second model is trained to correct the errors of the first model, focusing on the misclassified points. By doing this, the model is iteratively refining the predictions and focusing on the difficult examples.
Repeat the Process: This process of training models to correct the errors of previous ones continues for several iterations. Each model adds value by improving the overall predictions made by the ensemble.
Combine the Models: After all models have been trained, their predictions are combined to make the final prediction. In classification tasks, the final prediction may be determined by a majority vote (the most frequent prediction across all models), while in regression tasks, it could be a weighted average of the predictions from all models.
Common Boosting Algorithms
Several boosting algorithms have been developed over the years. Here are some of the most widely used ones:
1. AdaBoost (Adaptive Boosting)
AdaBoost is one of the earliest and most popular boosting algorithms. It works by adjusting the weights of misclassified instances, so that the next model in the sequence pays more attention to them. AdaBoost is typically used with decision trees as weak learners, but it can also work with other types of models. The key features of AdaBoost are:
- It starts with equal weights for all training instances.
- After each iteration, the weights of misclassified instances are increased, forcing the next model to focus on those harder-to-classify points.
- The final prediction is a weighted sum of the individual model predictions.
Pros: AdaBoost is simple to implement and effective, even for large datasets. It is also less prone to overfitting than some other models.
Cons: AdaBoost can be sensitive to noisy data and outliers, as these can heavily influence the final model.
2. Gradient Boosting
Gradient Boosting is another popular boosting algorithm that works by optimizing a loss function through a series of iterations. Unlike AdaBoost, which uses reweighted instances to focus on misclassified data, Gradient Boosting builds each new model to minimize the residual error (the difference between the predicted and actual values). This is done through gradient descent.
In Gradient Boosting:
- The algorithm calculates the gradient of the loss function (i.e., the error) and uses this to train the next model.
- Models are added iteratively to minimize the residual errors of previous models.
- Final predictions are made by combining the predictions of all models.
Pros: Gradient Boosting can handle complex relationships and produce high-quality models with high accuracy. It’s effective for both regression and classification tasks.
Cons: Gradient Boosting can be slow to train and may be prone to overfitting if not properly tuned.
3. XGBoost (Extreme Gradient Boosting)
XGBoost is an optimized implementation of Gradient Boosting, designed to be faster and more efficient. It is highly popular in machine learning competitions due to its speed and accuracy.
Key features of XGBoost include:
- Regularization: XGBoost incorporates regularization techniques to avoid overfitting, making it more robust.
- Parallelization: XGBoost can train models much faster than traditional Gradient Boosting by parallelizing the process.
- Handling Missing Data: XGBoost can handle missing data, making it more flexible in real-world applications.
Pros: XGBoost is highly efficient, performs well on structured datasets, and has a range of hyperparameters to fine-tune for optimal performance.
Cons: XGBoost requires careful hyperparameter tuning and can be computationally expensive for large datasets.
Why is Boosting Important?
Boosting is an essential technique in machine learning because it significantly enhances the performance of weak models. Here are some reasons why boosting is widely used:
- Increased Accuracy: By combining multiple weak models, boosting creates a stronger model that can make more accurate predictions, especially on difficult datasets.
- Better Handling of Imbalanced Datasets: Boosting can focus on harder-to-classify instances, which helps improve accuracy when dealing with imbalanced datasets.
- Effective for Complex Problems: Boosting is effective at learning complex patterns and relationships in the data, making it ideal for challenging problems.
Leave a Reply